



SEO
Home ![]() Search
Engine Optimization Articles
Search
Engine Optimization Articles ![]() Dynamic and Static Web Pages
Dynamic and Static Web Pages
Dynamic and Static Web Pages

Dynamic web pages are database-driven web pages and to achieve this, one uses server-side technology such as ASP, Cold Fusion, Perl, etc. Dynamic pages are created by the web server if a visitor defines a number of variables such as product ID, product specs, session ID, language, geographic location, search terms etc. These variables are accessed by the visitor by simply clicking links on the site.
Websites that can use databases to insert content into a webpage by way of a dynamic script like PHP or JavaScript are the ones most sought after. This type of site is called dynamic website. People choose dynamic content over static content because if a website has thousands of products or pages, writing or updating each static manually is a Herculean task.
Unlike static HTML pages, dynamic pages do not exist as individual files on the server and come into being only when they are requested by the user. Dynamic web pages may certainly be extremely useful for many reasons but create some difficulties for certain types of search engines.
As we all know, there are two types of URLs -
dynamic URL and
static URL.
A dynamic URL is a page address that is obtained from searching a database-driven web site or the URL of a web site that runs a script. In the static URLs, the contents of the web page remain unaltered unless the changes are hard-coded into the HTML. Static URLs are understandably ranked higher in search engine results pages and they are indexed faster than dynamic URLs. Static URLs are also more user-friendly.
The image below explains static and dynamic pages
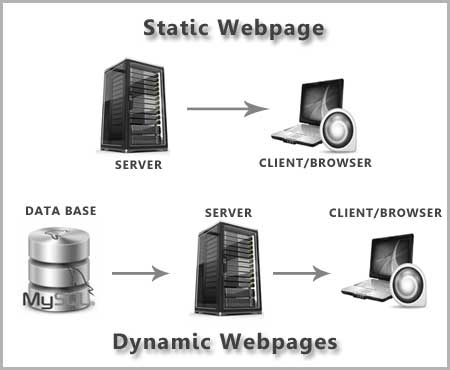
There is no denying the fact that search engines are not good at reading dynamic web pages for a variety of reasons - dynamic webpage does not physically exit on server, dynamic website has complex URLs such as "http://www.asif- iqbal.com?name=value&blabla%blabla@session_id@2226897&blabla=77 and search engine bots/crawlers usually have difficulty in reading these characters "?", "=", "@", "%", "$", "*", "&", "!" in URLs. Further, Search engine bots/crawlers might get stuck in an infinite loop, especially if the dynamic webpage has session id.
Search engines mostly use robot crawlers to locate searchable pages on web sites. Robots are also known by other names such as crawlers, spiders, gatherers or harvesters. These robots read pages and follow links on those pages to locate every page on the specified servers and for this reason, readable URLs are good and by far more helpful. It is certainly cumbersome and tedious to go back and recode every single dynamic URL into a static URL. This would involve colossal work for any website owner.
The simple answer, therefore, is to generate static pages from your dynamic data and store them in the file system and linking using simple URLs. For constantly changing information, you should set up an automatic conversion system. Most servers have a filter that can translate incoming URLs with slashes to internal URLs with question marks and this is known as URL rewriting. For either system, please ensure that the rewritten pages have at least one incoming link.
Search engine robots will follow this link and index your page. Pages which include images and links to other pages should use relative links from the base page rather than from the current page. This is because the browser sends a request for each image by putting together the host and domain name with the relative link.
You may have many valid reasons to use static URLs in your website whenever possible. When this is not possible, you can keep your database-driven content as the old dynamic URLs, but provide end-users and search engines a static URL to navigate and it will still be your dynamic URLs in disguise.
If you are willing to use Search Engine Genie's Services
Contact
Us Or Mailto search
engine genie support desk
 |
 |
 |
 |