




Caffeine update datacenter goes offline:
Written by seg
@ 9:33 PM
permanent link on
Wednesday, November 18, 2009
| Post a Comment |
0
comments
![]()
![]()
When i visit that URL i get this message:"Thank you! We appreciate all the feedback from people who searched on our Caffeine sandbox. Based on the success we've seen, we believe Caffeine is ready for a larger audience. Soon we will activate Caffeine more widely, beginning with one data center. This sandbox is no longer necessary and has been retired, but we appreciate the testing and positive input that webmasters and publishers have given."
Most of our sites and our client sites are doing exceptionally well in this particular datacenter and i am happy to see it go live. One particular client whom we have been doing work for about 2 years now is doing exceptionally well. I am sure he will be the happiest person to see his site do so well. I feel this update brings a lot of happiness among users.
Matt cutts says in his comments the delay for a full role out is because of the worry it will create on webmaster's mind. https://www.mattcutts.com/blog/google-caffeine-update/ I was just stunned to see a response like that from a senior Googler. Because Google gave a damn for anyone's website. I can remember back in 2003 when we had the great infamous Florida update it make lots of webmaster cry and even lot who depended on Google went out of Business. People were yelling but Google never cared. Good to see Google care for webmasters a lot these days.
Labels: Mattcutts
Caffeine update - upcoming Caffeine update in Google updated my Matt cutts
Written by Search Engine Genie
@ 12:34 PM
permanent link on
Tuesday, August 11, 2009
| Post a Comment |
2
comments
![]()
![]()
He tells us to check Google ranking changes in this datacenter "http://www2.sandbox.google.com/". Only big visible change i see here is the wonderful update timings of sites. Almost all results show updated in few minutes or few hours which is amazing.
But one funny thing i noticed which i searched for "Google blog" i got this funny result with site links.

We usually see the notice "this site may harm your computer" when there is a virus alert and the site is infectious. Here a sitelink for Google blog looks very similar to a virus injection warning. :-) thats funny i hope Google realizes that fast or they might loose some people who are afraid to click a link that says a look alike warning like that.
Labels: Mattcutts, Search Engine Optimization
Mattcutts Transcript - Google or twitter
Written by Search Engine Genie
@ 12:48 PM
permanent link on
Thursday, July 16, 2009
| Post a Comment |
0
comments
![]()
![]()
Here is a fun peculiar question from martino
Which search media does return the more reliable information: Google or twitter?
Don't go hate of twitter and make people bust heads twitter has many many great users and its great for breaking real time sort of news its fantastic for asking your friends and Google on the other hand we try to really give reliable reputable information so if you sort it by data twitter is fantastic or if you want to ask a question that has been there for a while then Google is great for that and try both for different situations if you don't have as many friends then you might not be able to get the answer for the question that you want it answered and i wouldn't be surprised if spammers actually see traffic on traffic as whoa. Because if you only sort it by date then any news that spammers post will come onto that so they are different they are different for different things i would say do what ever works best for you.
Labels: Mattcutts
Mattcutts discusses PR sculpting:
Written by power
@ 9:35 PM
permanent link on
Thursday, March 26, 2009
| Post a Comment |
0
comments
![]()
![]()
Matt Cutts, talks about the best ways to stop Google from crawling your content, and how to remove content from the Google index once we've crawled it.
Sebastine explains pretty well on that topic:
As for password protected contents, are you sure that you don't index those based on 3rd party signals like ODP listings or strong inbound links?
You totally forgot to mention the neat X-Robots-Tag that allows outputting REP tags like "noindex" even for non-HTML resources like PDFs or videos in the HTTP header. That's an invention Google can be very proud of. :)
@Ian M
Actually, Google experiments with Noindex: in robots.txt, but that's "improvable".
Currently Google interprets Noindex: in robots.txt as (Disallow: + Noindex:). I think that's completely wrong, because:
1. It's not compliant to the Robots Exclusion Standard.
2. It confuses Webmasters because "noindex" in robots.txt means something completely different than "noindex" in meta tags or HTTP headers.
3. Mixing crawler directives and indexer directives this way is a plain weak point that will produce misunderstandings resulting in traffic losses for Webmasters and less compelling contents available to searchers. All indexer directives (noindex,nofollow,noarchive,noodp, unavailable_after etc.) do require crawling when put elsewhere. I do Webmaster support for ages and I assure you that Webmasters will not get it. If nobody understands it and adapts it, it's as useless as Yahoo's robots-nocontent class name that only 500 sites on the whole Web make use of.
4. The REP's "noindex" tag has an implicit "follow" that Google ignores in robots.txt for technical reasons (it's impossible to follow links from uncrawled pages). When I put a robots meta tag with a "noindex" value, then Google rightly follows my links, passes PageRank and anchor text to those, and just doesn't list the URL on the SERPs. When I do the same in robots.txt Google behaves totally different, for no apparent reason. (Of course there's a reason but I want to keep this statement simple.)
Having said all that, I appreciate it very much that Google works on robots.txt evolvements. Kudos to Google! However, please don't assign semantics of crawler directives to established indexer directives, that doesn't work out. I see the PageRank problem, and I think I know a better procedure to solve that. If you're interested, please read my "RFC" linked above. ;)
@all
Do not make use of experimental robots.txt directives unless you really know what you do, and that includes monitoring Google's experiment very closely. If you've the programming skills, then better make use of X-Robots-Tags to steer indexing respectively deindexing of your resources on site level. X-Robots-Tags work with HTML contents as well as with all other content types.
Labels: Mattcutts
Selling links not wrong when you are Matt Cutt's Friend.
Written by Search Engine Genie
@ 8:57 AM
permanent link on
Tuesday, June 24, 2008
| Post a Comment |
0
comments
![]()
![]()
Barry is a long term friend to Matt Cutts and now in recent Matt's Post https://www.mattcutts.com/blog/google-webmaster-chat-tons-of-fun/ he gave a bunch of links to Barry for posting the 2nd webmaster live chat transcript. He does this because Barry is his friend and if anyone else posts the same script he just ignores them.
When the first Google webmaster live chat happened we were the first to post the script here . Even Matt Cutts knew we posted but he just ignored them as if it never existed. I can understand now how important its to attend Search Conferences and make Matt your friend.
You can have 2 advantages.
1. Sell as much text links as you want and still Matt cutts will ignore you and will be happy to be your friend.
2. Will give bunch of links from his blog since he likes you.
Lets follow the new rule of Text link advertising be friend with Google and you will be ignored even if you sell 1000 links.
Vijay,
Labels: Mattcutts, Search Engine Optimization
Mattcutts reiterates Yahoo Directory has plenty of Pagerank Internally.
Written by Search Engine Genie
@ 7:08 AM
permanent link on
Sunday, June 15, 2008
| Post a Comment |
2
comments
![]()
![]()
Matt Cutts replied this thread " It looks like it's just a matter of canonicalizing upper vs. lowercase as to why some of the subdirectories look the way they do in the toolbar. I just wanted to reiterate that the Yahoo Directory has plenty of PageRank in our internal systems."
Labels: Mattcutts, Webmaster News
Matt cutts on web spam in recent web 2.0 Conference Oreilly
Written by Search Engine Genie
@ 12:43 PM
permanent link on
Sunday, May 04, 2008
| Post a Comment |
1
comments
![]()
![]()
"Spammers are human," Cutts said. "You have the power to raise their blood
pressure. Make them spend more time and effort...If spammer gets frustrated,
he's more likely to look for someone easier." How? Forthwith, some tips for
those who manage their own or others' Web sites. • Use captcha systems to make
sure real people, not bots, are commenting on your site. He uses a simple math
puzzle--what's 2 + 2?--but he also likes KittenAuth, which makes people identify
kitten photos. One blogger merely requires people to type the word "orange" into
a field. "The vast majority of bots will never do that," Cutts said. •
Reconfigure software settings after you've installed it. A little modification
of various settings will throw bots off the scent. "If you can off the beaten
path, away from default software installations, you'll save yourself a ton of
grief," he said. • Employ systems that rank people by trust and reputation. For
example, eBay shows how long a person has been a member and how satisfied others
are with transactions with that person. • Don't be afraid of legitimate
purveyors of search-engine optimization services. "SEO is not spam. Google does
not hate SEO," Cutts said. "There are plenty of white-hat SEO (companies) who
can help you out." Registering your Web site at Google's Webmaster Central site
can help find bogus search-engine optimization tricks others may use on your
site, such as keywords written in white text on white backgrounds, he added.
Speech by Matt Cutts was very information he did say white hat SEO companies are definitely recommended and its not difficult to find a good SEO company. He recommends comment authentication since there are a lot of blog spam lurking out there. Mattcutts has been a major link between webmasters and Google.
Crawl Date in Google's Cache: Matt Cutts Video Transcript
Written by Search Engine Genie
@ 11:47 AM
permanent link on
Sunday, April 20, 2008
| Post a Comment |
0
comments
![]()
![]()
Ok everybody we have a new illustration today. Vanessa Fox of Google webmaster central blog talked about this some people like to learn visually , some people like to learn screen shots, so I thought ill make a little movie so this is going to be a multi media presentation the 2 media we are buying today are skill and peanut butter red ones. So lets talk about Googlebot and how it crawls the web. First off what are the red imminent represent, well everyone knows red is bad so these are going to be 404s. The Googlebot is crawling around the web and it sees a 404 sucks it down and then later on it will come back to try to check it again.
So what are the purples mean well everybody knows purple means a http status code of 200 OK, That's the only thing that it could possibly represent. So in other words Googlebot comes along and it sucks up the page and we got the page just fine. So we got a 404 we got couple http 200s so life is pretty good next, now lets talk about the cache crawl date and what they represent. So we are not able to tell that easily but this is purple we got two greens , purple and the rest greens. So what do you think the green imminent represent? Everybody knows the green imminent are great we know it's the good ones so green represent a status code of 304. So in a browser Googlebot comes to a page they say hey I want to copy this page or you can just tell me if the page has been modified since I indexed and that the page if the page has not been modified since a certain date you can get 304 status back saying that this page hasn't changed and all that Googlebot has to do is to ignore that page. SO this is what Googlebot does , this is going forward in time so in other words we crawl a page we get 200, the next 2 times Googlebot crawl the page it gets a 304 which is the If Modified Since that said that the page hasn't really changed. And later on then here the webmaster actually changed the page and we see this purple that again means the page has been changed since the last crawl and now we get a 200 since the page is actually fetched.
Now going forward the page didn't change so the web server is smart enough to return a 304 status code for each one of the visits by Googlebot. Now the thing that is interesting is if you want to check whether Googlebot cached the page it will show the last date that the page was last retrieved. But the interesting thing is that until recently the post that we checked on this date and this date it will still give us the very first time that we fetched that page. Now you fetch the page again and it would show this cache crawl date and this would continue and may be for 6 months if the page and the page hasn't change we would still show the old cache crawl date. So the change in policy in what we are doing is if we check on this date and on this date to see if the page has changed we will now show that date in the cache crawl date. So in other words as Googlebot comes along , slipping stuff along it might used to a page which might look pretty old we update that so as we know about even if the page is changed or not we update the crawl date in the cached page so the pages look more fresh in the cache crawl date even for the fact we are showing the date to reflect in the fact that we have actually recently checked the pages has changed.
Labels: Mattcutts, Mattcutts Video Transcript, Video Transcripts, Videos
Lightning Round matt cutts video transcript
Written by Search Engine Genie
@ 11:14 AM
permanent link on
| Post a Comment |
0
comments
![]()
![]()
Alright this is Matt Cutts Coming to you on July 31st Monday 2006 this is probably the last one ill do tonight so lets see if I can kind of do a lightning round. Alright Peer rights in and says
Is it possible to search just for homepages? I tried doing minus in URL html and in URL htm , so and so URL php , ASP but that doesn't filter out enough. That's a really good suggestion peter having thought about that, fast used to offer something like that I think all they did was look for a tilde in the URL I would file that as a feature request and see if people are willing to prioritize that if we are willing to offer that. My guess is it will be relatively low on the priority list because the syntax you mentioned subtracting a bunch of extensions would probably work pretty well.
I got to clarify something about strong Vs Bold, Emphasis Vs Italic. There is a previous question where somebody asks whether it is better to use bold or it is better to use strong because bold is where it was used in olden days when the dinosaurs were roaming the earth and strong is what the w3c recommends. And that time last night I thought that we barely , barely like we prefer bold over strong and I said its not the most part that you would worry about it and the next thing is that a engineer really took me to a code and showed me in live and I can see that Google treats bold and strong exactly the same weight. So thank you for that paul I really appreciate it. And also I saw an other part of the code where the M ( emphasis ) and italics are exactly treated the same. So there you have it so mark it like W3C wants to do it, do it semantically well , do it and don't worry about just small tags because Google will treat just the same way of both the versions.
Ok next in Lightning round Amanda Asks " Do we have more kiddy posts in the future"?
I think we will, I tried to bring my cats here around me but they are afraid of lights and just jumped off. Ill see if I can bring them in future.
Tom Html asks, Where is Google SST, Google guest , google weaver, google market place, google RS 2.0 and other services discovered by tony rescow?
I think its very clear for tony to do a dictionary tag again, services check-in but I am not going to talk about what all those services are.
A preview Joseph Hunkins asks what many topics will be there in duplicate contents as yet, a little bit of a preview on one of the other sessions is on video but I think what I basically want to talk about is it will be there lot of people will be there it will be shingling
What I want to say is Google detects duplicate contents all the way from crawl to all the way people see things when searching. We do stuff that's exact duplicate detection and we do stuff that's near duplicate detection so we do a pretty good job all the along the line like detecting dupes and stuff like that.
And so the best advice I give is to make sure your duplicate contents like the page that has contents as much similar as possible to make it look as much different as possible if they are truly different content. A lot of people talked about word versions or .doc compared to html files typically no need to worry about that if it has similar contents on different domains may be French and an other version in English you really don't need to worry about that, again if you do have the exact same content may be for a Canadian site and for a .com site so probably we will roll the dice and see which ever one looks better to us and just show that but it wouldn't necessarily trigger any sort of penalty or anything like that if you want to avoid you can make sure your templates are very, very different but better if the contents are similar its better to show us which ever is the most ideal for representation and guess the best anyway. And Thomas writes in and says does Google index and rank blog sites different than regular sites?
That's a good question not really, somebody asked me whether links from gov, edu's , and links from two level deep govs and edus like gov.pl or gov.in are the same as .gov?
The fact is really we don't have much of a difference in a way to say hey this is a link from ODP or .gov or .edu and so on. There is no some sort of special boost its just that those sites have higher Pagerank because more people tend to link to them and reputable people link to them so blog sites there aren't anything distinct unless if you go off to blog search ofcourse and its blogs and totally restrained to blogs. SO in theory we could rank them differently but most part its just a general search the way it falls out.
Alright thanks.
Labels: Mattcutts, Mattcutts Video Transcript, Video Transcripts, Videos
Google Terminology - Matt cutts Google quality engineer transcript
Written by Search Engine Genie
@ 1:14 PM
permanent link on
Friday, April 18, 2008
| Post a Comment |
0
comments
![]()
![]()
Hello Everyone I am back, Ok Why don't we start off with a really interesting question. Dazzling donna wrote in all the way from Louisiana she says matt I mentioned before I love to see do the fine type of post, find terms that you at Google use that we non Googlers might get confused about. Things like data refresh etc. You may have defined them in various places but one sheet type list will be great.
Very good question, at some point I need to do a blog post about host, Host Vs Domain and bunch of stuff like that. Some of people had been asking question about June 27th to July 27th so let me talk that a little bit more in the context of a data refresh vs an algorithm update versus an index update. So ill use the metaphor of a car. Back in 2003 we were crawling the web and indexing the web once in every month when we did that that was called an index update algorithms could chance, data could change so everything could chance just in one shot. So that was pretty big deal webmasterworld will name those updates. Now that we pretty much crawl and index some of our datas every single day it's a ever flux its always going on through a process the biggest change in the people's tendency are algorithm updates. You don't see any index updates any more because when we moved away from the monthly update cycle the only time you might see them is you might be completing an index which is incompatible with the old index. So for example if you do simulation of CJK its China, Japan and Korea to under stand this you might have to completely change your index and go to an other index in parallel. So index updates are relatively rare , algorithm updates basically are when we change our algorithm. So may be its with the scoring a particular page you said you know Pagerank matters this much less or this much more or something like that. And those can happen pretty much any time so we call that asynchronous because whenever we get an algorithm update and the tally rates positively and it improves quality, in improves relevance we go ahead and push that out and an other smaller change is called data refresh that is essentially like you are changing the input to the algorithm , changing the data that the algorithm works on. So an index update with a car metaphor would be like changing a large section of the car things like changing the car tyre whereas an algorithm update is like changing a part in the car may be a changing out the engine for a different engine or changing or other main parts of the car, a data refresh is more like changing the gas in your car every one or 2 weeks or 3 weeks your change will always go in and will see how the algorithm works on that data. So for most part data refreshes are more common one thing we got to be very careful about is how safely we check them, some data refreshes happens all the time so for example we compute Pagerank continually and continuously so its always back of Machines refining Pagerank based on incoming data and pagerank goes out all the time anytime when we make an update to the index it happens pretty much every day.
By contrast some algorithms are updated every week every couple of weeks so those are data refreshes that are happening in a slower page. So the particular algorithm that people are interested in, on June 27th and July 27th those algorithms, actually those algorithms happen to be live for over a year and a half so you are seeing data refreshes that you are seeing that people see as a way for sites to rank.
In general if your site has been affected go back to your site take a fresh look at see if there is anything that might be exceedingly over optimized or maybe hanging out in SEO forums for such a long time that I need to have a regular person come in and take a look at the site and see if its ok to me. Or if you tried all the regular stuff and still it looks Ok to you then I would keep building regular good content and make the site very useful and if the site is useful then Google should fight hard to make sure its ranking where it should be ranking. That's about the most I can give about June 27th and july 27th data refreshes because it does goes into our secrets also a little bit but that hopefully gives you a little bit of an idea about the scale the magnitude of different changes.
Algorithm changes happen a little more rarely and data refreshes are always happening and sometimes it happen from day to day or sometimes week to week or month to month
Thanks
Matt Cutts
Labels: Mattcutts, Mattcutts Video Transcript, Video Transcripts
Trust Rank Explained by Matt Cutts - transcript mini
Written by Search Engine Genie
@ 1:31 PM
permanent link on
Wednesday, April 16, 2008
| Post a Comment |
0
comments
![]()
![]()
Hello Matt: I was talking about the Trust Rank and you said something is going on with the Trademark or I don't know I couldn't concentrate but so can you tell something more about it.
Mattcutts: Yes let me know talk about that a little bit. What is trust rank everybody is curious about that. Its kind of nice to ask , everybody has a vague view about it. So turns out there was someone in Yahoo , Peterson and some other people at yahoo and they wrote a paper about something called Trust Rank and what it does is it tries to treat reputation and like physical mass how it goes around the web and what physical properties does trust have and its really interesting stuff but its completely separate from Google.
And so couple of years ago at the exact same time Google was working on a Anti-phishing filter and part of that we need to come up with a name for it so they filed for a trademark and I think they used the name Trust rank and it was really a coincidence yahoo had a Trust Rank as a search research project and we had Trust rank as a trademark so everybody talks about Trust Rank, Trust Rank and so if you ask five different people they will have five different opinions about exactly what trust rank is.
Labels: Mattcutts, Search Engine Optimization
Matt Cutts Discusses Webmaster Tools - mattcutts video transcript
Written by Search Engine Genie
@ 6:37 AM
permanent link on
Tuesday, April 15, 2008
| Post a Comment |
0
comments
![]()
![]()
I am up in the Kirkland office today, Up here for an outside little bit planning and they said you see why don't we throw together video and like 10 minutes or less. So we said alright lets give it a shot. So we are thinking about some of the common things you do with webmaster console or some topics webmasters want to hear about people want to go to webmaster console and check their backlinks.
They also like to know if they have any penalties there are a lot of really good stats in the webmaster console. One thing I had been hearing questions about is how do I remove my URLs from Google. So why would you want to do this well suppose you are in school and you accidentally left your Social Security Number of all your students up on the web or your store you left people's credit card numbers. Or you are running a forum and suddenly you are spammed full of porn by a Ukrainian forum spammer which happened to a friend of mine recently. So whatever the reason you want some URLs out of Google instead of getting URLs into Google. Lets look at some of the possible approaches some the different ways you can do it.
What ill do is , ill go through each of these ones and will kind of draw a Happy Face by one or two I think are specially good as far as getting the contents out of Google or perhaps abandoning them from getting into Google the first place. So the first thing a lot of people say is ok I just don't like to a page is a secret server page Google won't know or ever find it that way I don't have to find a way up of showing up the Search Engines. This is not a great up roach and ill give you a very simple reason why. We actually see so many people surf to a page and then serve to an other web server and that causes your browser to create a referrer in the HTTP in browser codes the header status which showed up before will show up on the other web server. And that other web server shows hey these are the top referrers to my page and may be that's a clickable hyperlink then Google can crawl that other web server and find a link to your so called secret web page. So its very weak to say "you know what I don't want to link to it ill just keep it a secret and no one will ever find about it". For what ever reason somebody will call from that page somebody will link from that page, somebody will refer from that page or as I said somebody will accidentally link to that page and that's you know if there is a link on web to that page there is a reasonable reason that we might find it so I don't recommend anyone using that its relatively very weak way. An other way you can do is something called .htaccess. Ok that sounds little, let me tell you very simply. This is a very simple file that lets you do simple things like redirect from one URL to an other URL the thing I am specifically talking about is can password protect a sub-directory or even you can protect your entire site now I don't think we provide a .htaccess tool in the webmaster tools but that's ok there are a lot of them out on the web and if you do a simple search like .htaccess tool or wizard something like that you will find one that will say like a password protective directory and it can even tell a directory and generate one for you and you can just copy and paste that onto your website.
So this is very good why is this strong why am I going to draw a Happy face here. Well you got a password on that directory Googlebot is not gonna guess that password you know we are not going to crawl that directory at all and we if we cant get to it . It will never show up in our index. This is very strong, very robust and efficient for the search engine because someone has to know the password to get into that directory. So this is one of the two ways I really really recommend this is a preventive measure so if already got chance to get into it you already had it vulnerable on your site so if you plan in advance and you know what the sensitive areas are going to be just put a password on there and it will work really well.
Ok here is an other way one that a lot of people know about called Robots.txt. This one has been here for over a decade atleast 1996 and essentially its like a electronic no trespassing sign it says here are areas of your site that Google or other search engine are not allowed to crawl, we do provide robots.txt tool in the webmaster console so you can create one and test out URLs and see if Googlebot is allowed to get to them , you can test out like the different variants of Googlebot like the Image-Googlebot is allowed to get to it and you can take new robots.txt files for test drive so you can say how about I try this for my robots.txt could you crawl this URL, or could you crawl this URL and you can just try it out and make sure it works ok. That's nice because other wise you are going to shoot yourself on your foot say you make a robots.txt and make it like and it has a syntax error and say it keeps everybody in or keeps everybody out that's going to cause a problem. So I recommend you take that tool for a test drive and see what you like and then you can put it live.
Then ok robots.txt is kind of interesting, different search engines have different polices of uncrawled URLs , ill give you a very simple example way, way, way back in days sites like Ebay.com , Nytimes.com don't want anyone to crawl their site so they had a robots.txt file that said
Useragent: *
Disallow: / ( everybody )
So this will not allow any search engines to crawl even if you are a well behaved search engine. So that is kind of problematic so you are a search engines and somebody typed in Ebay and you cannot return Ebay.com it looks kind of dumb and its like what we decided or what we our policy still is we will crawl this page but we will not show a uncrawled reference sometimes we can make it look pretty good about it. Sometimes if there is a entry to nytimes.com in the Open Directory project ( ODP ) we can show that snippet from the ODP and show it for nytimes.com as a uncrawled reference and for users its good even though we are not allowed to crawl and we infact did not crawl it. So robots.txt is to prevent crawling but it wont completely prevent that URL from completely showing up in Google so there are otherways to do it. Lets move on to NOINDEX meta tag. What that simple says for Google atleast is don't show that page at all in search engines so if we find Noindex we will completely drop it from Google search results we will still crawl it but we wont actually show it if somebody does a search in search result query for that page. So its pretty powerful works very well and very simple to understand there are couple complicating factors, yahoo and Microsoft even if you use the noindex meta tag can show a reference to that page, they wont return the complete the full snippet and stuff like that but you might see the link to that. We do see some people having problem with that for example you are a webmaster and you put up a noindex meta tag and put it up on your site been shifting around in developing your site you might forget and might not take that noindex meta tag down so very simple example. The Hungarian version of BMW I think has done this, there is a musician ( harper ) you probably heard about is pretty popular has a noindex metatag its still there and if you are the webmaster of that site we love you to take that down. So there are various people in google would have said may be we should not show the snippet of the url but show a reference to that URL. There is one other corner case on this noindex which is we can only abide by that meta tag only if we had crawled that page of we haven't crawled that page we haven't seen that meta tag and we haven't know its there. So in theory its possible if you link to that page and we don't get a chance to crawl that page we don't see a noindex and we don't drop It out completely. So there are couple of cases where you have atleast the reference which will show up in google and pretty much yahoo and Microsoft will always have a reference to that page if you use the noindex metatag.
So here is another approach you can use that is the Nofollow tag that can be added on individual links. This is an other type weak approve since inevitably say there are 20 links to that page may be I am going to put a Nofollow on all of them may be it's a sign in page may be if you are a expedia.com and you want to add a Nofollow on my itineraries it makes perfect sense right. Why would you want Googlebot to crawl into your itineraries because that's a personalized thing. But inevitably somebody links to that page or you forget to have a page which not every single link with a Nofollow so its very common that, ill just draw a very simple example suppose we have a page A and we have a Nofollow link to page B,
We will follow that link we will drop it out of our link graph we will drop it off completely so we wont discover page B because of this link but now like say there is an other guy on page C that wants to link to page B we might actually follow that link and will eventually end up indexing page B so you can try to make sure every link to a page is no-followed but sometimes its hard to follow that every single link is no-followed correctly so this like the NOINDEX does have some weird corner cases where you can very easily a page gets crawled since not every link has the Nofollow-ed or in the noindex case we can actually get to the page and end up crawling the page and end up later seeing the noindex tag. So lets move on to an other powerful way I tend to use this whenever a forum gets by porn spammer recently. And that's the URL removal tool. So .htaccess is great as a preventive measure you put a password on it no-one can guess what it is, no search engine's are going to get in there, it wont get indexed. The other thing you can do is if you do let the search engines in before and you want to take it down later you got the URL removal tool. We have offered the URL removal tool for atleast 5 years probably more for long time it sat on pages like services.google.com and it's a completely self service that runs 24/7 but just recently the webmaster console team has integrated the URL removal tool into the webmaster console. Much much simpler to use the UI is much better what it helps is it will remove the URL for 6 months and if that was a mistake and if you removed your entire domain which you don't need to then you need to email Google's user support telling them hey I didn't mean to remove my entire site can you revoke that and someone in google have to do that. Now you can do it yourself also its powerful and well accessible in webmaster console. Anytime you can go in to webmaster console and say hey I didn't mean to remove my entire site and remove that request and that request gets revoked very quickly. So to use the webmaster console its not that hard to prove that you are the owner of the site, you just need to make a page on the root of the website , root of the directory or root of the site to say yep here is a little signature in the text file to say that this is my site. Once you prove that this is my domain then you get a lot more stats and this wonderful little URL remove tool. And it can remove a very nice level of speed in there you can remove a whole domain, you can remove a sub-directory thing you can even remove individual URLs and you can see actually the status of all the URLs you have put a request to be removed, initially it will show a status that the request is pending and later it will show that the URL removal has been processed/ removed. This will change the status to revoke. You can give a reason what ever you have like hey I got the credit card numbers, Social security numbers of what ever sensitive you had there removed and you want to revoke the URL removal from Google's index. In other words its save to crawl and index again. So all the ways to remove the URLs or churning up URLs from showing up in Google there are a lot of different options some of them are very strong like the robots.txt, noindex but they do have these very weird corner cases like we might show the reference to the URL in varied situations so that ones that I definitely recommend is the .htaccess that will prevent the search engines and people from getting into the first place and for Google we have the URL removal tool so if you got URLs crawled that you don't want to show up in Google's index you can still get them out and get them out relatively quickly.
Thanks Very much Hope that was very helpful.
Matt Cutts.
Why we prepared this Video transcript?
We know this video is more than a year old but still there are people who have questions about their site and want to listen from a Search Engine Expert. Also there are millions of Non-English people who want to know what's there in this video so a transcript is something that can be easily translated to be read in other languages. We know there are people with hearing disability who browse our site this is a friendly version for them where they can read and understand what's there in this video.
This transcript is copyright - Search Engine Genie.
Feel free to translate them but make sure proper credit is given to Search Engine Genie
Labels: Mattcutts, Mattcutts Video Transcript, Video Transcripts, Videos
Supplemental Results - Matt cutts video transcript
Written by Search Engine Genie
@ 6:35 AM
permanent link on
| Post a Comment |
0
comments
![]()
![]()
Ok we got some supplemental results questions david writes in he says "Matt should I be worried about this, site table1.com returns 10,000 results site:table1.com -intitle:by returns a 100,000 results all supplemental. David in general I wouldn't worry about this I want to explain the concept of beating path.
So if there is a problem with one word search in Google that's a big deal if it's a 20 word search that's obviously a less of a big deal its because its often not a big impact. Supplemental results team takes reports very seriously and acts very quickly on them, But in general in something in supplemental results is mostly off path than our main web results. And once you start getting into negation or negation by a special operator like -intitle then its pretty off the main path and you are talking about results estimates its not the actual web results but the estimates for the number of results. The good news is there are couple of things which can help in bringing up the result estimates more accurate ah atleast I know 2 things that can influence an infrastructure.
Deliberately trying to make the site results more accurate
Other one is the change in the infrastructure to improve our raw quality
But side benefits is the it gives the estimated number of results to be more accurately when it involves the supplemental results. SO there are atleast a couple of changes that might make things more accurate but in general once you start to get really far from the beginning path -intitle all these stuff specially for supplemental results I wouldn't worry that much about the result estimates, historically we haven't worried too much since not many people were interested. But we do hear more people sort of saying yes I am crazy about this so you need to put more effort into that.
Erin writes and says that "I have a question on redirects, I have one or more pages of various moved across various websites I use classic ASP and shows how he gave response for 301. He said these redirects are setup for quite a while and if he runs a spider on them it reads the redirect fine. This is probably an instance where you would have seen this happen in supplemental results, so here is how we can go about things. There is a main web results Googlebot and a supplemental results Googlebot so the next time the supplemental results Googlebot visits that page and sees the 301 it will reindex accordingly and things will refresh and so on historically the supplemental results have been a lot spidered data that is not refreshed as it is done for the normal web results. If you check the cache anybody can verify that the results and the crawl date vary so the good news is that the supplemental results are getting fresher and fresher and the effort is made to make them quite fresh.
For example Chris writes "I like to know more about the supplemental results, it seems while I want in vacation my sites got put there, I have one site that had a Pagerank of 6 and it got put in supplemental results since like May. So like I talked about the fact that there is a new infrastructure in our supplemental results I mentioned that also in blog post and I don't know how many people have noticed it but certainly I have said that before I think it was in the indexing timeline in fact so as we refresh our supplemental results and start to use new indexing infrastructure in the indexing results in supplemental results the net effect is the data will be a lot fresher also I wouldn't be surprised that I have some URLs in supplemental results I wouldn't worry about it that much and over the course of summer the supplemental results team will see all the reports that they receive especially things off the beat infact as I said like site: and operators that are hysteric they will be working on that those return the sort of results that everybody will naturally expects so stay tuned on supplemental results and already its lot fresher and lot more comprehensive than it was and I think its just going to keep improving.
Labels: Mattcutts, Mattcutts Video Transcript, Video Transcripts, Videos
Optimize for Search Engines or Users? - Matt cutts video transcript
Written by Search Engine Genie
@ 6:24 AM
permanent link on
| Post a Comment |
0
comments
![]()
![]()
By the Way I shoot my disclaimer to somebody in Google video's team and he said matt you look like you had been kidnapped so maybe I should be some rocket boom world map or something like that out there you guys worry more about the information that how pretty it looks I am guessing, alright todder writes in my simply question is this "which do you find more important in developing and maintaining a website search engine optimization or end user optimization?"
And that says ill hang up and listen, todder that's a great question well both are very important and I think if you don't have both you wont do the best you want to do, I think search engine optimization its harder to be found if you don't have end user optimization you don't get conversion you don't get people to really stay and really enjoy your site post in your forum or buy your product or anything else. SO I think you do need both the trick in my mind is to try to see the world such that they are the same thing. You want to make it look best so that the user's interest and the search engine interest are as aligned as you can and if you can do that then you are usually in very good shape because you have compeling content you have people want to visit your site. It will be very easy for your visitors to get around and for search engines to get around. And you don't have to do any weird tricks anything you do for search engines are also be shown to users. So I think you need to balance both of them.
Tedsey writes in with a couple of interesting questions "can you point us to some spam detection tools, I want to monitor my site to make sure I come out clean and show that I am valid among the no good spamming competitors. Well if you sure want to check spamming some tools you can use.
First of in Google we have lot of tools to detect and flag spam but most of them are not out side of Google one thing you can look at is Yahoo site explorer which is good it actually shows backlinks for specific pages or per domain I think that could be very handy. There are also other tools that could show you everything in one IP address, if you are going to be on a virtual host you are going to share with a lot of perfectly normal sites but sometimes there might be a lot of bad spam sites on that Ip address and you could end up in the wrong way. So you got to be careful that you are not automatically considered part of something wrong. As far as checking your specific site is concerned I will definitely hit Google sitemaps in webmaster console that will tell you crawl errors or other problems we found.
Second question tedsey asks "What about the cleanliness of code for example W3C, any chance that the accessible problem will leak into the main algorithm?" People had been asking me this for a long time and my typical answer is normal people write code with errors it just happens all the time. Eric one of the founders of the HTML standards said 40% of all html pages have syntax errors and there is no way a search engine can remove 40% of its contents from its index just because somebody didn't validate or something like that. So there are a lot of content especially content that is manmade students that already use or things like that its very quality but probably doesn't validate. So if you asked me a while a go I would have said yah I don't have a signal like that in our algorithms and its probably for a good reason that said now T.V Raman had done the work on accessible search and you know I am sure in future somebody can look at for a possible positive signal. If you have pass through the quality you have to pass through vigorous validation and stuff like that in general its great idea to go and get your site validated. But I wouldn't put that in top of your list, I would put on making compelling content and making a great site at the top of your list and once you have got that you can go back and dug your eyes and check whether you got good accessibility as well. Well you always want to have good accessibility but validating and closing off that last few things usually that doesn't matter a lot for search engines.
Why we prepared this Video transcript?
We know this video is more than a year old but still there are people who have questions about their site and want to listen from a Search Engine Expert. Also there are millions of Non-English people who want to know what's there in this video so a transcript is something that can be easily translated to be read in other languages. We know there are people with hearing disability who browse our site this is a friendly version for them where they can read and understand what's there in this video.
This transcript is copyright - Search Engine Genie.
Feel free to translate them but make sure proper credit is given to Search Engine Genie
Labels: Mattcutts, Mattcutts Video Transcript, Video Transcripts, Videos
Matt Cutts on Duplicate Content and Paid Search - Video Transcript
Written by power
@ 9:14 PM
permanent link on
Monday, April 14, 2008
| Post a Comment |
0
comments
![]()
![]()
Ya,Ya
Yep
Ya it was funny at the end, That when I laughed, Ok u have seen most of it, so she gave puffy examples instead, good willow bad willow, good centre good centre,
It worked ya it worked
I think its interesting, it's a deep issue, Its kinda tough 1 too, so really good question of claiming your content but then, we were talking about that couple of days ago with a bunch of goggle's, And we always have to worry about how it can be found, and so, what if somebody innocent doesn't claim their content, and then, and then smart man that comes along, and claims everybody else's content,
And so when u have got your whole frequency and u have to worry about people taking your content in between the time u scroll your pages that's a tricky thing, Now nice thing is some thing like blog search, we get a pinning, we get to scroll it, we can see it rite then, so the time frame in blog search is so much faster, so we get to little bit more on ownership, so I think we hoping to try in a lot of different things but it is a difficult issue.
Yep,
Ya absolutely, some people say oh dear Google tell me what to do. And we are not, like your the web master, it's your site, u do whatever u want on your site. And that's your rite. But that's our in depths, and here we are finding what we think are best practices, and if you wanna do really well and good in Google, I think most webmasters do, here are some you can do well but you know people will always have rites to take on more risk but, we wanna tell them that there is a lot of risk involved in that, and so people should think about before they do it
Well, and I think its interesting, because we have said we don't like as early a s 2005 but we have not talked about this recently, so even though it wasn't going to be incredible popular with seos, because seos like to have as many tools in their tool boxes as possible I said it time to revise at this topics, I we can remind people about it, and so even though I knew there would be a lot of comments Its important to reintegrate use the stance and we mite be taking stronger action on it in the future so its sort of giving people the heads up, its like giving them a little bit of notice, They can choose what they wanna do but they should also think about the possible consequences of what they choose to do.
I think we would be good to make a lot of that, I talked about it during the q& A, our guide lines are pretty minimal, I wanna give the people the idea of what to do,. Triangular links, pentagonal links, Hexagonal links n stuff like that
We were saying, how about four way links, no that's against the Google line, some were like 5 way links at some point u wanna think you wanna give the idea n then and people can infer from that but I think it would be nice to have few more details, we have looked at, how can provide few more scenarios, we take some from the we set on the blog and cooperate that into the web master guide lines.
Its possible its, its more like it, we have it at the back of our mind, So for example within the past few months we have revised our webmaster help in general to say no not everything is 100% automatic, No human have ever touched that. Because u need really room for social search so it is an ongoing process we talked about search results and how its not a good process to not have tones of search results that don't add a lot of value so v do go back, for example we also added a spy-ware, Trojan, and that sort of stuff, so it is kind of living document we always go back every few months what we need to add and how are we gonna make it better.
Labels: Mattcutts, Mattcutts Video Transcript, Video Transcripts, Videos
Matt Cutt Discusses Snippets - Mattcutts Video Transcripts
Written by power
@ 5:33 AM
permanent link on
| Post a Comment |
0
comments
![]()
![]()
So just to remind everybody, I am visiting the Kirkland office and they said you know what lets grab a video camera and just talk about a few things and have a little bit of fun and put these videos up on the web.
So one of the things that we thought we'll talk about is a snippet, what are the different parts of the snippet? How do we choose which part of the snippet to show and not show?
So since we are up in the specific North West let's talk a little bit about Walkthrough this snippet of starbucks and what that it looks like and talk through the different parts.
Alright the first thing you'll see is the title and that's typically what you set on the title of your webpage. So "starbucks Homepage" is what Starbucks use for www. Starbucks.com. Now in general Google reserves the rights to try to change the snippet and make it as useful as possible for users always doing all kind of different experience. Like is it more helpful to show two dots or three dots, you want to end with dots, you want to start with leading spaces, how do you find the most relevant part of the page? And try to say this is what we should be showing. But the majority of the time you have a great deal of control of how about how things get presented.

So in this case starbucks uses the title "Starbucks Homepage" and just a quick bit of SEO advice for starbucks, "Home page" na a few people might search for that but I might say something like "Starbucks coffee" where people are more likely to search for that okay enough of the free advice for starbucks. The next thing that you see is something that we call as the snippet

So next thing that you see is something that we call has the snippet, "Starbucks coffee company is the leading retail coaster and brand of specially da dad
Now where does that snippet come from? It can come from many different places, suppose for example we weren't able to call the URL, May be for whatever reason it was down and we couldn't get a copy of it, we don't have anything from the page not even the Meta description tag nothing at all. In those cases we sometimes do rely on the open directory project. So starbucks I wouldn't be surprised if it's in the open directory so if we weren't able to call the page we might pull the description form there. Another thing we sometimes do is pull the description from a place within the page. So suppose you got a phonebook and you're looking for somebody's name and the name is way down at the bottom it's a lot more helpful to show that person's name from the bottom of the page and may be a few words from either side of that person's name than it is to show like the first fifty words of the page, so we do try to find the most relevant parts of the page Some times its single snippet, sometimes its multiple parts of the page and combine that together and people are little bit of context that this page is really I am looking for. But neither of these two is at the open directory project or directly from the within the content of page body itself. And in this case I looked into it and view source that this is the Meta description tag.
So we did post on the Google webmasters blog just for a while that how these snippets get picked, and it turned out you can use your own Meta description tag and in many cases that is exactly what we will choose to use as a snippet. But you want to be careful because this is a very fine snippet, but maybe there is some other snippet that can work better. You know people would read it and say oh I really want to click through and find out more about that. You can experiment with different Meta descriptions and see that the one that gets more clicks is the one that works better. But we use several different sources of data when deciding how to pull things together. In this case starbucks is also a company so we show a little + box where if you want you can click the plus box and you can expand and see a stock chart for Starbucks. You can see if they are doing well in the market.

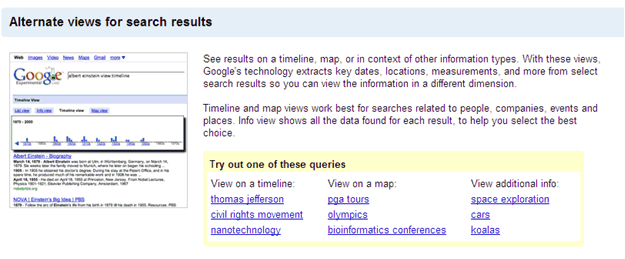
There are a lot of these different options. For example if you are having an address on your page many times it will show a plus box and it will say view a map of and then you can have your address. And we are always looking for new ways to surface interest in data. If you go to google.com/experimental we do have views where you can look at search results on a time lines, search results on a map, you can even see all the search results for images and even measurements. So if you going to search for Koalas or Koala bear, you can say show me the measurements. Then it will show you all the things like oh Koala bears are 20 pounds and stuff like that which is really helpful.
In general or whatever interesting information you have on your page that user will be interested in well try to surface that or show relevant information like stock quote or stuff like that. There is also something like that's a little subtle and unnoticed is that we have bolded the starbucks, that's because someone has queried for starbucks. So often times if you do a query and if those keywords are on the page, well make them bold so that people know what you typed is actually on that page. We know about morphology, we know about synonyms. If you typed in car, we can sometimes return search results that have automobiles. But that wouldn't be bolded, or wouldn't be likely to be bolded and what more likely is whatever you typed in is what's going to be bolded. So in that case it gives you little more information and shows how relevant that page.
Working down a little bit you can see the URL which you are actually going to end on, 12K stands for 12 kilobytes which is relatively small page that means it will load pretty quickly. And then you see the cached links, imagine for example the site is down. May be you are the webmaster of the page and you accidently deleted it, but then you can look at the cache page and you could recover the source of that page, then you could put it back up again. The cache page also has really interesting features. If you click on it, It shows us the last crawled date, you can say ok well today is October 7th look at the cached page and oh we last crawled the page on October 6th then you know how precise the search results are.
Sometimes if we are very precise, then we can show an indicator right on the snippet here below ( next to 12k) that we crawled 17 hours ago to let you know that we are very precise.
Similar Pages shows you related pages to start about may be other businesses or other pages that you might be interested in. And a lot of time if you are logged in to Google you will "NOTE THIS"
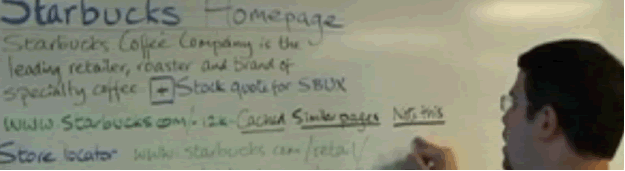
If you are a student of if you are doing research it's really handy it works with Google note book and all it does is that it saves this off, as I am doing my research I want to save this result can be able to come back to it and may be aggregate it later and may be aggregate all the stuff together on some research chapter.
And then this is really nice, this is what actually to be a little indented on the snippet. But what we call this is site links. There are a couple of things we need to know about site links. First off, no money is involved. Somebody always asks, "So did starbucks pay some money to get them?" No it's purely algorithmic.

And the second thing is it is purely algorithmic it's not done by hands so it's not like we go to store box and say may be we are interested in store locator and then nutrition and stuff like that. But there is a lot of sophistication going on here for example on this page the title is actually Starbucks Store Locator but you don't need to see that most of the times so we can say store locator and if you look at this page the title is actually like Beverage details and something and in fact the link to that page is nutrition.
So we are sort of selective we try to pick the sort of little description that gives people enough information and make sure where they can say "Oh! The store locator is what I want and I am going to go directly there" or I wanted to find out if I get a Mocha how many calories is that so I can go straight to the nutrition. So it's completely algorithmic and no money is involved in that. And then when we get to the bottom if we have a lot of results for a page may be we show one or two and then we will say you know what may be you want to see more results from Starbucks and what that lets you have is a more diversity so you can see one or two results from starbucks and maybe you want to see other results for that query. That sure helps in clear diversity of that page and at the same time lets you dive deeper if you want to.
So that's a very quick tour on what a Google snippet is. Hopefully it was helpful.
Labels: Mattcutts, Mattcutts Video Transcript, Video Transcripts, Videos
How to structure a site? - Mattcutts Video Transcript
Written by power
@ 8:57 PM
permanent link on
Sunday, April 13, 2008
| Post a Comment |
0
comments
![]()
![]()
Ok As you can this is the closest I can get to a World Map, Did you know there are 5000 languages spoken across the globe, how many does Google support? Only about a 100 still a long way to go.
Alright, Lets do some more questions. Todd writes in he says Matt I have a question, One of my client is about to acquire a domain name very related to their business and has a lot of links going to it. He basically wants to 301 redirect to the final website and the acquisition. The question is will Google ban or impose a penalty for doing this 301 redirect. In general probably not you should be ok, because you specify its closely related, anytime there is a actual merger of two businesses together, two domains very close to each other do a 301 redirect and merge together its not a problem. However if you are a Music site and you are suddenly getting links from Debt consolidation and online cheap YAHYAHYAH, that should be problem but what now you have planned to do is fine and you should be ok.
Barry writes in "What's the right way to theme a site using directories you put the main keyword in the directory or on the index page? If you are using a directory do you use a directory for each set of keywords?
This is a good question, I think you are thinking too much about your keywords and not about your site , this is just for me I prefer a tree like architecture, so everything branches out even, nice like a branch sort of thing and also it will be good if you are breaking down by topics so if you are selling clothes and you have sweaters as one directory and shoes as an other directory and something like that, if you do something like that what you will end up with is your keywords do end up in directories, So as far the directories vs the actual Html file it doesn't matter with Google screwing up with it, So actually I think if you break it down by topic and make sure that your topic is broken down by keywords. Then I think if your user type of keywords and find your page then you are in pretty Good shape.
Aright Joe writes in, If a Ecommerce site has too many parameters say it has punctuation marks, dots etc and its un index able is it ok to be within Google's guidelines and serve static html pages to Googlebot to index instead. This is something that I will be very careful of because if you end messing this up you will be doing something called cloaking which showing different content to users and different content to Googlebot and you need to show the exact same content to both users and Googlebot. So my advice is to go back to the question I asked about whether or not the parameters in URLs are indexable and unified so that both users and Googlebot see the same user directory. And if you are going to do something like that, definitely that's going to be much better saying that what ever html paying you are going to show to the Googlebot , if users go to that page and if they stay on the same page and not redirected or sent to an other page then you are fine. They need to see the exact same page that Googlebot saw that's the main criteria you got to be careful about that.
John writes in he says "I would like to use AB split testing on the static html pages, will google understand my PHP redirect for what it is or will Google penalize my site for assumption of Cloaking, If there is a problem is there a better way to split test?. That's a Good question if you can I would recommend split test in a area where search engines aren't going to index it. Because when we go to a page and you reload and show different content then it does look a bit strange so if you can please use robots.txt or .htaccess file or something that Googlebot doesn't index it. Saying that I wouldn't do a PHP redirect , I will configure in a server to serve 2 different pages parallel. One thing to be careful about and I touched on this a while ago in a previous session that you should not do anything special for Googlebot just treat it like regular user that's going to be the safest thing in terms of not being treated as cloaking.
And lets wrap up, Todd asks an other question he says hi Matt here is the real question, Ginger or Marian? I am going to go with Marian.
Why we prepared this Video transcript?
.
Labels: Mattcutts, Mattcutts Video Transcript, Video Transcripts, Videos
Qualities of a good site - Matt cutts Video Transcript
Written by power
@ 8:46 PM
permanent link on
| Post a Comment |
0
comments
![]()
![]()
Hello again lets deal with a little more questions, I hope its work lets give it a shot. Raf writes in some comments on Google sitemaps please. He says does updates on sitemaps depend on page view of the site? I feel that's not the case page views are not the factor on how things are undated in sitemaps, you know there are different pieces of data in sitemap so imagine you know there are a file of different sets of data. They could all be updated in different times and in different frequencies and typically they should be updated within days or worst case within weeks however as far as I know it doesn't depend on page views.
Lets deal an other one "What are your basics ideas and recommendations on increasing sites ranking and visibility in Google? " Ok this is a meeting topic definitely a longer issue ok so lets go ahead and dive into it? So Lets go and see the number one thing most people make mistake on SEO is the they don't make the site crawlable. So I want you to look at your site in search engines eyes or user text browsers do something and go back to 1994 and use lynx or something like that. If you could get through your site only in text browser you are going to be in pretty good shape, because most people don't even thing about crawl ability. You want to also see on things like sitemaps on your site or also you can use our sitemaps tools in addition to that once you got your content, content that is good content, content that is interesting, content that is reasonable that's attractive and that will make some actually link to you and then once your site is crawlable then you can go about promoting, marketing, optimization your website. So the main thing that I would advice or thing about the people who are relevant to your niche and make sure they are attracted. So if you are attached to a doctor since you run a medical type of website make sure that doctor knows about that website if he knows about your site it might be appropriate for him to link to your website.
You also should be thinking about a hook some thing that holds your visitors it could be really good content newsletters, tutorials, I was trying to setup all these video stuff trying to make it look semiprofessional and there is tutorial by a company called photo flex something they said here is something like keylike, throw etc and BTW they say you need to by our equipment to do that. That's really really smart, infact another photography site that I went to I saw they syndicated the other site tutorials to add on their website. That could be a great way to get links you can also You should also think on places like reddit, digg, Slashdot you know social networking sites myspace this sort of stuff. Fundamentally you need to have something that sets you apart from the pack once you have something like that you are going to be in very good shape as far as promotion your site is concerned. But the biggest step making sure your site is crawlable after that , making sure you have good content and finally make sure you have a hook which makes people really love a site return to it and really bookmark it.
Alright lets do an other one "what condition asks
Alright this one is a good one. Laura McKenzie says does Google favor bold or strong tags. In general we probably favor bold a little bit more but just to say it more clear its so slight that I wouldn't really worry about it. When you do it do what ever is best for yours and oh I don't think its going to give a little bit of boost in google or anything like that. Like I said its relatively small so I recommend you do what is best for users and what ever is best for your site and then not worry about that much after that.
I think that's it,
Thank you,
Why we prepared this Video transcript?
We know this video is more than a year old but still there are people who have questions about their site and want to listen from a Search Engine Expert. Also there are millions of Non-English people who want to know what's there in this video so a transcript is something that can be easily translated to be read in other languages. We know there are people with hearing disability who browse our site this is a friendly version for them where they can read and understand what's there in this video.
This transcript is copyright - Search Engine Genie.
Feel free to translate them but make sure proper credit is given to Search Engine Genie.
Labels: Mattcutts, Mattcutts Video Transcript, Video Transcripts, Videos
Matt Cutts Discusses the Importance of alt Tags - Mattcutts Video Transcript
Written by power
@ 9:34 PM
permanent link on
Saturday, April 12, 2008
| Post a Comment |
0
comments
![]()
![]()
But the general problem of you know, detecting what an image is and been able to describe it, is really really hard; so you shouldn't count on computer being able to do that, instead you can help Google with that. Now let's see what this image might look like, if you look at the right this might be a typical image source "img src - "DSC00042.JPG" you know, you got your image tag, u describe what the source is, here is DSC because it is a digital camera, you know blah blah blah 42.JPG, that doesn't give us lot of information, right? You won't be able to say this is cat with a ball of yarn we don't want to say, here is number that gives a virtually zero information, if you go down a little bit, here is sort of information that we want to show up, you won't be able to say this is Matt's cat, Amy Cutts, with some yarn; right? & you know that's not a lot of words but it adequate describes the scene, it gives you a very clear picture what's going on.
It includes words like yarn, a word like Emmy Cutts, which is all completely relevant to that image and it isn't stuffed with tons of words like cat, cat, cat, feline, lots of cats, cat breeding, cat fur with all sorts of stuffs. So you want to have a very simple description, sort of included with that image; how do you do that? If you look here,
 "Matt Cat, Emmy, Cutts, with some yarn> you can see this image tag, image source and an ALT tag which stand for alternative text, and if so somebody is using a screen reader, or they can't load the image for a reason, your browser can sow you this alternative text and you know it is very helpful for Google. Now you can see what's going on, different people and people who are interested in accessibility can also get a good description what the image is, you are not spamming; this is a total of 7 words, if u got 200 words in your ALT text, you really don't need a ton of words because 7 is enough to describe a scene pretty well. Right? If you get 20 or 25, that's even getting a little bit out there, 7 is perfectly fine, you are talking whatz going with in the picture itself.
"Matt Cat, Emmy, Cutts, with some yarn> you can see this image tag, image source and an ALT tag which stand for alternative text, and if so somebody is using a screen reader, or they can't load the image for a reason, your browser can sow you this alternative text and you know it is very helpful for Google. Now you can see what's going on, different people and people who are interested in accessibility can also get a good description what the image is, you are not spamming; this is a total of 7 words, if u got 200 words in your ALT text, you really don't need a ton of words because 7 is enough to describe a scene pretty well. Right? If you get 20 or 25, that's even getting a little bit out there, 7 is perfectly fine, you are talking whatz going with in the picture itself.You can also look for alternative tags like tidal and things like that but this is enough to help Google to know whatz going on in the image. You can go in advance, you could think about naming your image something like 'Cat and Yarn.JPG' but we are looking for something light weigh and easy to do, adding an ALT tag is very easy to do and you should pretty much do it in all of your images, it helps your accessibility and it can help us (Google) to understand whatz going on in your image.
Why we prepared this Video transcript?
We know this video is more than a year old but still there are people who have questions about their site and want to listen from a Search Engine Expert. Also there are millions of Non-English people who want to know what's there in this video so a transcript is something that can be easily translated to be read in other languages. We know there are people with hearing disability who browse our site this is a friendly version for them where they can read and understand what's there in this video.
This transcript is copyright - Search Engine Genie.
Feel free to translate them but make sure proper credit is given to Search Engine Genie
Labels: Mattcutts, Mattcutts Video Transcript, Video Transcripts, Videos
Some SEO Myths - Mattcutts Video Transcript
Written by power
@ 9:08 PM
permanent link on
| Post a Comment |
0
comments
![]()
![]()
Alright, I am trying to upload the last kick to the Google videos. So we will see how it looks while I am waiting I think I can do a few more questions and see if we can knock a few out I am realizing that with this video camera that I have got I can do about 8 minutes length of video before I get to the 100 megabytes limit then I have to use the client uploader so ill probably make it into chunks of 5 to 8 minutes each.
So Ryan writes - He says can you put us out of some myths where having too many sites on the same server, for having sites on IPs that look similar to each other, but having them include the same Javascript of a different site. In general if you are a average webmaster this is something that I haven't have to worry about. Now I have to tell a story about Tim Mayer and I on a penalty panel. Someone said hey you took all my sites out he said both Google and Yahoo did and I didn't really have that many, so tim saw that guy and asked so how many sites did you have?
And the guy looked little sheepish for a minute and then he said well I had about 2000 sites so well there is a range right? Say if you have 4 or 5 sites and if they are all different themes or different contents you are not in a place where you really need to worry about. But say if you have 2000 sites you ask yourself do you have enough value added content to support 2000 sites the answer is probably not. Its just that if you are a average guy I wouldn't worry about being on the same IP address and I definitely wouldn't worry about being on the same server that is something that everyone does. The last one Ryan asked about Javascript there are a lot of sites that do this, Google adsense is javascript included this is something that is common on the web I don't have to worry about it at all, but now again if you have 5000 sites and you are including the Javascript that does some sneaky redirect then you need to worry but that is something that you do on a few sites that is entirely logical and using Javascript I wouldn't worry at all.
Alright Aaron write in - its kind of interesting question? I am having a hard time understanding the problems that we face when we launch a new country. Typically we launch a new country with millions of new pages at the same time additionally due to our enthusiastic PR team we get tons of backlinks as well as press news during every launch. So they say the last time they did this they didn't do very well they launched a site for Australia and they didn't do very well at all.
Aaron this is a good question primarily because the answer to this somewhat changed since the last time we talked someone asked this question when we were in a conference in New-York and I said just go ahead and launch it you don't have to worry about it , it may look a bit weird but it will be just fine. But I think if you are launching your site will millions of web pages you got to be a little more cautious if you can. In general if you are launching with that many pages its probably better to try and launch a little more softly so a few thousand pages and add a few thousand more and stuff like that it could very well be, millions of pages are a lot of pages. Wikipedia is like say how many 5 or 10 million pages so if you are launching that many pages make sure you find ways to scrutiny and make sure those are all good pages. Or you might as well find yourself not as good as you hoped for.
Alright quick question; classic nation writes in and says What's the status on Google images and whether we will be able to hear about the indexing technology of the future?
Actually there was a thread about this on webmasterworld we just did an index update, just did I think last weekend for Google images, Actually I was talking to someone on the google images team they are always working hard, there is a lot of stuff you may have seen there might be new updates in future where we will be bringing new images that the main index has and stuff like that but they are always working on making Google images index better.
Labels: Mattcutts, Mattcutts Video Transcript, Video Transcripts, Videos